Machine Learning-Based Prediction of Korean Triage and Acuity Scale Level in Emergency Department Patients
Article information

Abstract
Objectives
Triage is a process to accurately assess and classify symptoms to identify and provide rapid treatment to patients. The Korean Triage and Acuity Scale (KTAS) is used as a triage instrument in all emergency centers. The aim of this study was to train and compare machine learning models to predict KTAS levels.
Methods
This was a cross-sectional study using data from a single emergency department of a tertiary university hospital. Information collected during triage was used in the analysis. Logistic regression, random forest, and XGBoost were used to predict the KTAS level.
Results
The models with the highest area under the receiver operating characteristic curve (AUROC) were the random forest and XGBoost models trained on the entire dataset (AUROC = 0.922, 95% confidence interval 0.917–0.925 and AUROC = 0.922, 95% confidence interval 0.918–0.925, respectively). The AUROC of the models trained on the clinical data was higher than that of models trained on text data only, but the models trained on all variables had the highest AUROC among similar machine learning models.
Conclusions
Machine learning can robustly predict the KTAS level at triage, which may have many possibilities for use, and the addition of text data improves the predictive performance compared to that achieved by using structured data alone.
I. Introduction
Ten million patients visited about 400 emergency departments in 2018 in Korea, and for most of those patients, the first emergency care they encountered was triage [1]. Triage, implemented in most modern emergency departments, is the process of accurately assessing and classifying severe symptoms to identify and provide rapid treatment to emergency patients. To this end, a patient's vital signs are measured, and a short history and examination is carried out as soon as the patient arrives at the emergency department by emergency physicians, emergency specialist nurses, or emergency medical technicians.
The Korean Triage and Acuity Scale (KTAS) was developed in 2012 based on the Canadian Triage and Acuity Scale [2]. Since 2016, it has been mandatory for all emergency centers across the country to use and assess patients visiting emergency departments with the KTAS. Centers are incentivized by the National Health Insurance Service through higher reimbursement rates for patients with higher KTAS levels [3]. Depending on the assigned KTAS level, a patient may wait for a set maximum amount of time until being evaluated by a physician [2]. It also supports the prioritization of the care provided in a busy emergency department to patients requiring urgent care. The KTAS was also recently shown to improve the length of stay and mortality rates in emergency departments [4].
As with most triage instruments, the KTAS classifies patients into five levels based on the patients' symptoms, with primary and secondary factors taken into account [5]. Primary factors involve characteristics common to most symptoms, such as consciousness, blood pressure, heart rate, respiration rate, fever, pain, presence of hemorrhage, and trauma. Secondary considerations are characteristics applied to specific symptoms. Although most criteria are objective indicators, subjective judgment by the triage staff influences the final level assigned to the patient.
Since triage is the starting point of care for emergency patients, it is important to be consistent in assigning KTAS levels. Hospitals employ dedicated personnel who have been certified by the KTAS Committee under the Korean Society of Emergency Medicine. The committee maintains a 6-hour training program for providers with more than 1-year clinical experience in an emergency department [6]. It is also important to maintain the quality of education, training, and evaluation, which is becoming more difficult to maintain, as the complexity of emergency care increases and more patients visit emergency departments nationwide. However, even with these systems in place, the problems of misclassification, over-triage, and under-triage still remain, due to the inherent complexity and uncertainty of triage.
Several previous studies have applied machine learning models to patients in intensive care units [78], and emergency departments [910]. Many studies have considered triage in particular, with most aiming to predict the outcome at triage [11121314]. One such example is a study that compared e-triage with the emergency severity index that showed more accurate results in predicting patient outcome [15]. Other efforts have focused on using not just structured data but also the text data generated. Sterling et al. [16] predicted disposition from the emergency department with only the triage text, and Hong et al. [11] used information collected at triage in addition to textual patient history to predict admission from the emergency department. However, there have been no attempts to predict or determine the outcome of a triage instrument with information collected during triage.
The aim of this study was to train and compare machine learning models in their ability to predict KTAS levels. We also hypothesized that free text nursing notes written during triage would provide additional information that would support prediction of the KTAS level.
II. Methods
1. Study Design, Setting and Data Source
This study was a cross-sectional study using data from a single emergency department of a tertiary university hospital with an annual census of 60,000 patients. Retrospective data of all visits by patients to the adult emergency department from November 2016 to June 2019 were included in the study. Encounters with missing data were excluded. All data processing was done with Python and related scientific libraries, pandas, and scikit-learn [1718]. This study and its protocol were approved by the Institutional Review Board of Seoul National University Hospital (No. 1910-071-1070) with a waiver of informed consent. No personally identifiable data was part of the dataset. Data used in this study was retrieved from the clinical data warehouse of Seoul National University Hospital Patients Research Environment (SUPREME).
2. Variables
Only variables collected during triage were used in the analysis. The data were divided into three separate datasets: structured data only, text of nursing triage notes only, and both structured data and nursing triage notes. The structured data included gender, age, date and time of arrival, chief complaint, route to the emergency department, pain location and intensity, vital signs (blood pressure, heart rate, respiratory rate, oxygen saturation), and level of consciousness. The chief complaint was selected from a set of 607 codes; the route taken by the patient to the emergency department was selected from five options (direct, refer from outpatient department, transfer from other hospital, other, or unknown); the pain location was selected from 10 possible locations; level of consciousness was selected from five options (alert, verbal response-disoriented, verbal responsestuporous, response to pain, and unresponsive). Some additional preprocessing was applied to the data. Arrival time was binned into 1-hour increments. Pain intensity scores that were written as text were converted into numeric form, for instance ‘6–7' was converted to 6.5. The nursing triage note is a free-form text note, usually one to three sentences in length that summarizes the patient's reason for visiting the emergency department written by the triage nurse. The outcome variable was the KTAS level assigned to the patient by the triage nurse on duty.
3. Natural Language Processing
Natural language processing (NLP) is a set of methods for analyzing human languages. Its purpose is to allow computers to process and understand the meaning of text. Because each language has specialized structures, such as characters, grammar, and words, NLP techniques have been developed for each specific language. In this study, most of the targeted documents were written in Korean. The domain of documents should also be considered when implementing NLP. The targeted documents were triage notes containing both Korean and English words. Most of them followed Korean grammar but had many English words designating medical concepts, such as symptoms, medications, and disease names.
To analyze the triage notes, we used soynlp, which is an NLP library of unsupervised NLP techniques written and available in Python [19]. Soynlp was used to tokenize the triage notes and normalize words. Unlike Western languages like English, Korean is not divided into meaning structures by spaces alone. For this reason, most Korean morpheme analyzer tools are based on pre-defined dictionaries. However, it is very difficult for these tools to analyze text that contain words that are not in the dictionary. This is called an out-of-vocabulary problem. In contrast, soynlp uses a word extractor based on probabilistic scores representing the likelihood of words. Therefore, it is more appropriate for analyzing documents with terminology that is used only in specific domains compared to any other Korean processing tools.
Because of the time pressure involved in writing the initial triage note, they usually contain abbreviations and shorthand notations. Because punctuation marks and numbers are usually removed in the preprocessing step before analysis, to maintain the meaning of notations that include multiple punctuation marks, the most common shorthand notations were fully spelled out. For example, abbreviations such as ‘n/v’ were replaced with ‘nausea vomiting’ and notations such as ‘(+/−)’, which would be completely removed by the preprocessing step removing punctuation, was replaced with the words ‘positive negative’. There was a total of 165 such replacement rules. After these abbreviations and shorthand notations had been removed, punctuation and numbers were removed, and all English text was converted into lowercase. No special preprocessing of the Korean language was performed besides tokenization with soynlp.
4. Machine Learning Models
In this study, we used logistic regression, random forest, and XGBoost to classify encounters. We applied a ridge logistic regression which uses L2 penalty to avoid multicollinearity and overfitting. Random forest is an ensemble model to combine predicted results of multiple decision trees [20]. In the process of learning a random forest model, each decision tree trains on a random sample of the training dataset with replacement, and a random subset of features is selected at each candidate split of trees. Through these methods, the trained trees become mostly uncorrelated. Averaging the results of less correlated models has the effect of reducing the high variance of each model's performance. As a result, the random forest has improved generalization performance. Random forest has been used by many scientists due to its performance; it was the best model for even the most comprehensive benchmarking studies [21]. XGBoost is an advanced model of gradient boosting machines (GBM), which trains many decision trees in a sequential and additive manner [22]. Although both GBM and random forest are based on decision trees, they train trees in different ways. In random forest, each tree is trained independently and becomes a so-called fully-grown tree, which overfits a subset of training dataset. GBM, on the other hand, learns small trees which may underfit the training set. However, trees in GBM are trained sequentially, and each tree is trained in consideration of the errors of other tree models in the previous steps. In this way, as more trees are trained, the error of GBM is reduced. XGBoost makes GBM's training scalable by distributed learning with several approximation methods to parallelize training. Since XGBoost was proposed, it has outperformed other algorithms in many studies and competitions [23].
To apply these algorithms, we structured the clinical notes using a bag-of-words model. In a bag-of-words model, each document is represented as a vector that has the same length as the size of the vocabulary [24]. In this study, the vocabulary was composed of unigrams, bigrams, and trigrams appearing in more than 0.1% in the entire document set [25]. However, in preliminary experiments, the use of unigrams alone yielded better performance. Using bigrams and trigrams caused the document vector represented by the bag-of-words model to become too long, leading the machine learning algorithms to fall victim to the curse of dimensionality.
Each of the models was trained and evaluated on three separate datasets: structured data only, text of the nursing triage notes only, and both structured data and nursing triage notes. Precision, recall, F1-score, and area under the receiver operating characteristic (AUROC) curve with 95% confidence interval (CI) are reported.
III. Results
A total of 142,972 patients visited the adult emergency department during the study period. Encounters with missing information (4,950 cases, 3.5%) were excluded from the study. The most common missing information was the location of pain (4,404 cases) followed by oxygen saturation (215 cases). After exclusion of the cases with missing information, a total of 138,022 patients were included in the study. The basic demographics of the patients can be seen in Table 1. The median age of the patients was 60 years (interquartile range, 43–72) and 52.2% were female. The KTAS levels were distributed as follows: 1,989 level 1 (1.4%), 16,098 level 2 (11.7%), 77,720 level 3 (56.3%), 36,045 level 4 (26.1%), and 6,170 level 5 (4.5%).
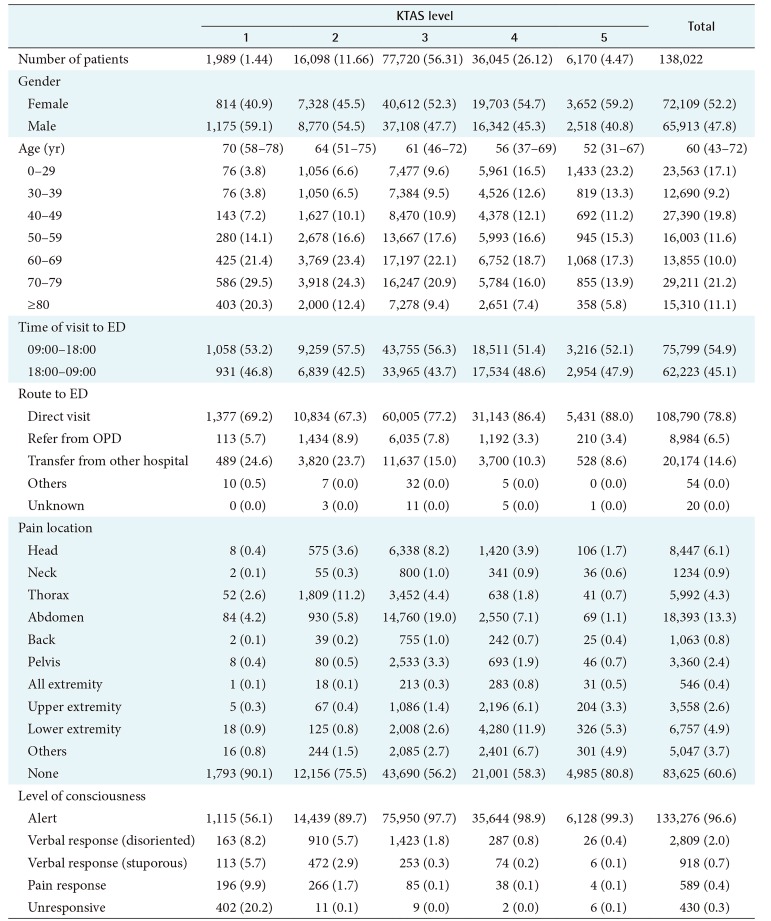
Patient demographics
Table 2 and Figure 1 present the classification results of the machine learning models on different subsets of data. The models with the highest AUROC were the random forest and XGBoost models trained on the entire dataset (AUROC = 0.922, 95% CI 0.917–0.925 and AUROC = 0.922, 95% CI 0.918–0.925, respectively). For each model, a similar trend is noticeable. The AUROC of the models trained on the clinical data is higher than that of the models trained on the text data only, but the models trained on all variables showed the highest AUROC among similar models.
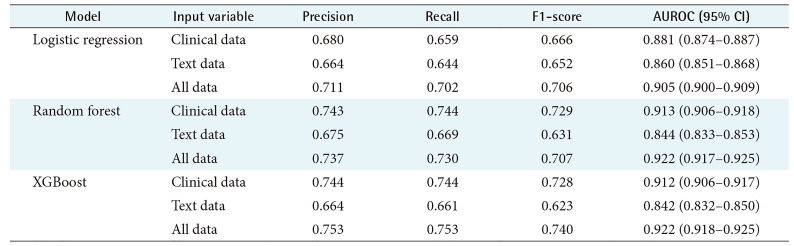
Classification results of machine learning models
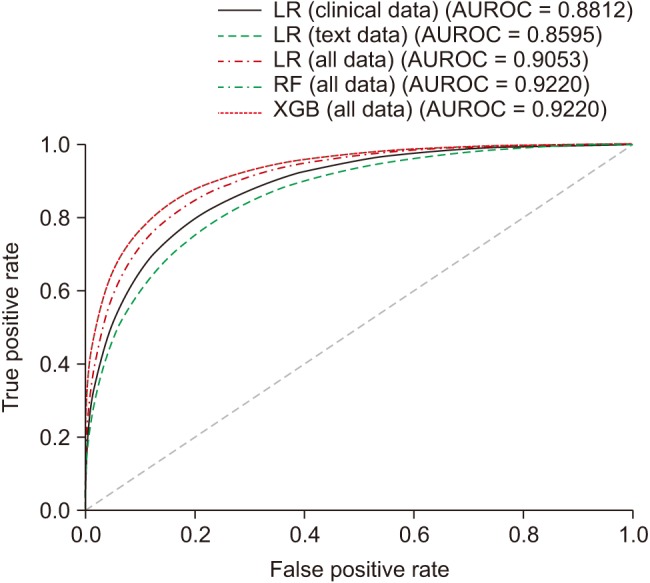
Receiver operating characteristic curve for selected machine learning models. AUROC: area under the receiver operating characteristic curve, LR: logistic regression, RF: random forest, XGB: XGBoost.
IV. Discussion
This study developed and compared several machine learning models using information collected during triage to predict the KTAS level. Our results indicate that machine learning algorithms can predict KTAS levels robustly during emergency department triage. To our knowledge, this is the first study to predict KTAS levels using information available during triage. Most of the studies reported in the literature have focused on predicting patient outcomes, but there are several possible uses of predicting not only the outcome but also the triage level.
As with many recent results, the random forest and XGBoost models outperform other machine learning algorithms, with XGBoost having the best F1-score (=0.740). It is also interesting to note that the AUROC of the random forest and XGBoost models using only clinical data outperformed the logistic regression model using the entire dataset pointing to the complex nonlinear relationships underlying the structured data.
As we hypothesized, the addition of nursing triage text data improved the prediction performance of all of the models studied, suggesting that there is information in the textual data that is not captured by the structured triage data, even with the minimal preprocessing of the text performed in this study. We only spelled out some common abbreviations and shorthand notations used in the notes, removed punctuation and transformed all English words to lowercase. We did not perform stemming nor lemmatization of Korean or English words, as lemmatization of Korean words still requires further work. The predictive ability of the models may be improved with more preprocessing of the text and further progress in Korean language processing.
Furthermore, even though the AUROC of the models may be acceptable in some instances, it cannot be denied that further improvements would be desirable. However, it must be noted that even between experienced triage nurses, the interrater weighted-kappa value was 0.772 [26], and 0.83 between triage nurses and experts in a retrospective review [27]. Although there is room for further improvement, even at its current state, the prediction model may be of assistance to triage personnel as an adjunct tool because expertise in triage instruments requires considerable training and may be limited in resource-constrained settings. This demand was clearly shown in a survey of triage nurses, where the most requested feature for a new tool being built was an automatic severity grade calculator for the emergency severity index, which is a widely used triage instrument [28]. Due to the inherent complexity and uncertainty involved with the triage of patients, misclassification, over-triage, and under-triage are always possible [27], and a rule-based decision support system for triage has been shown to reduce classification errors [29]. A support tool based on machine learning and NLP may also reduce triage errors and may be more robust to out-of-vocabulary terms than a rule-based system; this would be worth exploring in future studies.
There are several other possible use cases for an automated or supportive triage tool. In emergency dispatch centers and in prehospital ambulances where training and the maintenance of the quality of the larger pool of personnel may be difficult, an automatic tool may be used to support users in the field or as a quality-control monitoring tool. An automatic tool with triage capabilities developed for in-home use may also be employed by patients for self-assessment in deciding whether to go to the emergency department or not. If automated triage tools are shown to be useful, a separate tool developed for use in disaster zones and warzones may be valuable, where personnel trained in triage would most likely be overwhelmed.
This study had several limitations. As a single center study without an external validation dataset, the results cannot be confidently generalized outside of the study hospital. Another limitation is the possibility of systemic bias in the practices of different triage nurses. Since some subjective judgement is included into the determination of the KTAS level, any systemic bias would also be reflected by the model created and further limit generalizability. More recent techniques in natural language processing, such as recurrent neural networks and convolutional neural networks for text data, which are powerful tools, were not covered in this study. These can be explored in future studies.
In conclusion, machine learning models can robustly predict the KTAS level at triage, which may have many possibilities for use, and the addition of text data improves the predictive performance compared to that achieved using structured data alone.
Notes
Conflict of Interest: No potential conflict of interest relevant to this article was reported.