Feasibility Study of Federated Learning on the Distributed Research Network of OMOP Common Data Model
Article information

Abstract
Objectives
Since protecting patients’ privacy is a major concern in clinical research, there has been a growing need for privacy-preserving data analysis platforms. For this purpose, a federated learning (FL) method based on the Observational Medical Outcomes Partnership (OMOP) common data model (CDM) was implemented, and its feasibility was demonstrated.
Methods
We implemented an FL platform on FeederNet, which is a distributed clinical data analysis platform based on the OMOP CDM in Korea. We trained it through an artificial neural network (ANN) using data from patients who received steroid prescriptions or injections, with the aim of predicting the occurrence of side effects depending on the prescribed dose. The ANN was trained using the FL platform with the OMOP CDMs of Kyung Hee University Medical Center (KHMC) and Ajou University Hospital (AUH).
Results
The area under the receiver operating characteristic curves (AUROCs) for predicting bone fracture, osteonecrosis, and osteoporosis using only data from each hospital were 0.8426, 0.6920, and 0.7727 for KHMC and 0.7891, 0.7049, and 0.7544 for AUH, respectively. In contrast, when using FL, the corresponding AUROCs were 0.8260, 0.7001, and 0.7928 for KHMC and 0.7912, 0.8076, and 0.7441 for AUH, respectively. In particular, FL led to a 14% improvement in performance for osteonecrosis at AUH.
Conclusions
FL can be performed with the OMOP CDM, and FL often shows better performance than using only a single institution’s data. Therefore, research using OMOP CDM has been expanded from statistical analysis to machine learning so that researchers can conduct more diverse research.
I. Introduction
Federated learning (FL) is a new machine learning method that can be performed when data are distributed and difficult to centralize [1]. Initially, it was proposed by Google for use in mobile devices, but it is emerging as a suitable learning method in the medical area because it can achieve the effects of large-scale data learning without sharing the original data from multiple institutions [1–3]. FL performs learning using only the data held, without sharing the original data, and only shares the model weights to update the model. This method has two advantages: it can (1) reduce the risk of data leakage and (2) achieve privacy protection of data [4,5]. In particular, FL is very suitable for adoption in the medical domain because medical data are difficult to share with other institutions due to personal privacy protection reasons [6–9]. Since FL allows models to be updated by exchanging only the weights, it enables multi-institution research using medical data. As a consequence, FL can achieve higher performance than research conducted by each institution individually [6–9].
Before FL, it was common to share statistical analysis models through a distributed research network and perform meta-analyses of the values reported from each institution [10–12]. A representative distributed research network is the Observational Health Data Sciences and Informatics (OHDSI) [13]. In South Korea, the FeederNet was built based on the Observational Medical Outcomes Partnership (OMOP) common data model (CDM) used in the OHDSI. Feeder-Net is a distributed medical data analysis platform currently involving 33 institutions [14]. FL is performed in a data-distributed environment, so FeederNet is a very suitable environment for FL. The FL system requires a client module that performs machine learning at each institution, and a server module that aggregates model parameters and communicates with clients. Building this system on FeederNet enables high-quality research based on machine learning methods. To verify the feasibility of this FL platform, we conducted a pilot study using data from patients who received steroid prescriptions or injections, with the aim of predicting side effects such as bone fractures, osteonecrosis, and osteoporosis that could occur depending on the prescribed dose [15,16].
II. Methods
1. Implementation of the FL Platform
In order to efficiently perform FL on FeederNet, a distributed medical data analysis platform in Korea, the FL system was designed with a server-centered pulling method, unlike the client-centered FL method. Assuming that the CDM of each institution was the client, client control was only possible through FeederNet. Therefore, we designed a server-centered structure that could directly control FeederNet and aggregate functions from the outside. For this, application programming interfaces (APIs) were defined and implemented. The details of each API are shown in Table 1. The APIs include login, research file upload, research execution, status check, result inquiry, and downloading results.

List of federated learning APIs
The developed platform can be used after logging into FeederNet. The server manages scripts that perform predefined pre-processing and learning processes, and the server transmits this script to FeederNet. FeederNet runs the transmitted script in the machine learning environment of each institutional client and updates the progress. The client performs training and testing through script execution and saves the result in an independent space, which FeederNet manages. The server can then download the client’s weights and the results of the script after it runs, stored in an independent space from FeederNet. The server updates the global weights by performing federated averaging, which calculates average values by aggregating weight values from the results downloaded from FeederNet. Next, the server repeats this process by transmitting the script, including the global weights, back to FeederNet to proceed with the next round of learning. This process is shown in a sequential diagram in Figure 1.

Federated learning sequence diagram.
This approach has the advantage that the server manages only the number of rounds and weight information, and each client is able to perform training, testing, and saving the results on the platform stably.
2. Steroid Side Effects Study
To study steroid side effects, the CDMs of Kyung Hee University Medical Center (KHMC) and Ajou University Hospital (AUH) linked to FeederNet were used. The CDM versions KHMC_5.3.1_0.2 and AUH_5.3.1_0.6 were used. The subjects of this study were patients over 20 years old who had been prescribed oral or injected steroids from January 1, 2001 to December 31, 2019. We used SNOMED-CT codes for each disease and RxNorm codes for specific steroid drugs to retrieve the data. We excluded patients who had no records of hospital visits within 90 days after the prescription date, patients who had no records of hospital visits within 365 days before the prescription date, and patients for whom data errors make recognition impossible. The collected items are shown in Table 2.

Collected items
Learning was conducted using daily average dose, changes in vital signs, total dose, and duration of dose, which were calculated by extracting data from the CDM. The duration of the dose was calculated based on the start and the end dates of the steroid prescription for each patient. The total dose was calculated as the cumulative dose during this period, and the average daily dose was calculated over the same period. We also divided the duration of steroid use into short, intermediate, and long-acting intervals using 90-day intervals. Moreover, changes in vital signs were checked when the steroid was injected. The predicted outcomes were bone fracture, osteonecrosis, and osteoporosis. For each disease, positive patients were labeled “true” and negative patients were labeled “false.”
3. Machine Learning Model
Using the pre-processed data, each client trained the artificial neural network. Seventy percent of the data from each institution was used for training, and 30% was used for testing. For performance evaluation, the area under the receiver operating characteristic curve (AUROC) was calculated in the verification phase.
The model used for training consisted of a total of three layers, including an input layer, a fully connected layer, and an output layer, which applied the sigmoid activation function. Training was performed in 100 iterations.
For FL, federated averaging was performed using “coef_,” which denotes the coefficient in the decision function, and “intercept_,” which refers to the intercept value in the decision function, among the hyperparameters generated as a result of learning. Nineteen rounds of learning were conducted.
III. Results
The total number of patients for whom data were collected was 11,058 at KHMC and 28,596 at AUH. The numbers of cases of bone fracture, osteonecrosis, and osteoporosis were 459, 65, and 1,122 at KHMC and 284, 34, and 777 at AUH, respectively. Detailed information on the numbers of patients is shown in Table 3.
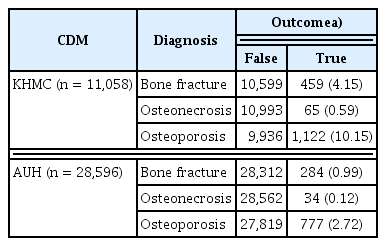
Number of patients queried in each CDM
As a result of learning using only data from each institution, for bone fracture, osteoporosis, and osteoporosis, the AUROCs were 0.8426, 0.6920, and 0.7727, respectively, for KHMC, and 0.7891, 0.7049, and 0.7544 for AUH, respectively. Details are shown in Table 4.

Learning results, expressed as AUROCs, using each institution’s data
The results of 19 rounds of FL for bone fracture, osteonecrosis, and osteoporosis are shown in Table 5. For KHMC, the AUROCs were 0.8260, 0.7001, and 0.7978, showing changes of −1.9%, +1.16%, and +0.27%, respectively, while the AUROCs for AUH were 0.7912, 0.8076, and 0.7441, showing changes of +2.7%, +14%, and −1.3% respectively.

Learning results expressed as AUROCs using federated learning
IV. Discussion
The results of this study showed that FL improved the overall performance of disease prediction compared to using only data from each institution. For KHMC, performance was improved by 1.16% and 0.27% for osteonecrosis and osteoporosis, respectively. For AUH, performance was improved by 2.7% and 14% for bone fracture and osteonecrosis, respectively. In particular, the performance for osteonecrosis significantly improved by 1.16% at KHMC and 14% at AUH. Considering the small number of positive data points for osteonecrosis, it can be seen that the performance was significantly improved by incorporating data from both institutions in the learning process. In some cases, the performance was low; an explanation for this may be that the model we used had only one fully connected layer, so the convergence was insufficient for a relatively large number positive data points. To solve this, conducting more rounds of iteration or training a complex model using more layers would seem to be required.
Since FL through FeederNet is performed in an independent virtual environment, the risk of personal information leakage is quite low. In addition, the server collects only numeric weights; therefore, it is impossible to guess the original data. These aspects of FL make it possible to conduct multi-institution research using medical data dealing with sensitive information and have the major advantage of protecting personal information.
We demonstrated that the FL platform designed through experiments worked well in a distributed research environment. In particular, in the past, statistical analysis was frequently performed using OMOP-CDM, but it has been demonstrated that FL enables artificial intelligence learning using multi-institution OMOP-CDM. Based on this study, we think that this method will provide an opportunity for more active multi-institutional research using medical data through FL in the future.
Notes
Conflict of Interest
This study was conducted with support by Evidnet. Jonggul Park and Jihyeong Kim supported the use of FeederNet. And Rae Woong Park is an editorial member of Healthcare Informatics Research; however, he did not involve in the peer reviewer selection, evaluation, and decision process of this article.
Acknowledgments
This study was supported by the research funding from Evidnet Inc.