Dorsal Hand Vein Pattern Recognition: A Comparison between Manual and Automatic Segmentation Methods
Article information

Abstract
Objectives
Various techniques for dorsal hand vein (DHV) pattern extraction have been introduced using small datasets with poor and inconsistent segmentation. This work compared manual segmentation with our proposed hybrid automatic segmentation method (HHM) for this classification problem.
Methods
Manual segmentation involved selecting a region-of-interest (ROI) in images from the Bosphorus dataset to generate ground truth data. The HHM combined histogram equalization and morphological and thresholding-based algorithms to localize veins from hand images. The data were divided into training, validation, and testing sets with an 8:1:1 ratio before training AlexNet. We considered three image augmentation strategies to enlarge our training sets. The best training hyperparameters were found using the manually segmented dataset.
Results
We obtained a good test accuracy (91.5%) using the model trained with manually segmented images. The HHM method showed slightly inferior performance (76.5%). Considerable improvement was observed in the test accuracy of the model trained with the inclusion of automatically segmented and augmented images (84%), with low false acceptance and false rejection rates (0.00035% and 0.095%, respectively). A comparison with past studies further demonstrated the competitiveness of our technique.
Conclusions
Our technique can be feasible for extracting the ROI in DHV images. This strategy provides higher consistency and greater efficiency than the manual approach.
I. Introduction
The purpose of biometrics is to identify individual physical or behavioral features based on their natural traits. Physical characteristics include fingerprints [1], the iris of the eye, the face, palmprints, and dorsal hand veins (DHVs) [2], while behavioral features consist of voice, gait, keystrokes, and signatures [3]. Given the lack of evidence and trust in the security of behavioral biometric information, most researchers have moved toward physiological characteristics. However, image quality and the surveillance angle are the major drawbacks of facial biometric systems [4]. Similarly, the problems with iris recognition systems include the setting of light illumination and eyeball movement while images are being captured [5]. Thus, many scholars have shifted their focus to DHV recognition systems.
DHV systems have several advantages over traditional recognition systems. The DHVs constitute a tree-like vascular network of blood located at the backside of the hand. The main benefit of using the DHVs as a biometric system is its high identification performance. The system detects only live hand veins, which have a low resemblance rate and high acceptability ratio [6]. The vein pattern is unaffected by humidity and temperature, since veins are located beneath the skin. Furthermore, although the DHV pattern varies from infants to 15 years of age [7], it remains unchanged unless a major accident occurs [8].
Although studies have been conducted in the past for DHV recognition using images captured by devices such as near-infrared (NIR) cameras [7], complementary monochrome metal-oxide-semiconductor (CMOS) cameras [9], and digital single-lens reflex (DSLR) cameras [10]. As benchmarks, the Bosphorus [11], North China University of Technology (NCUT) [12], Badawi [11], Indian Institute of Technology Delhi (IITD), and 11k Hands [13] databases are also freely available and publicly accessible. These public databases contain a large number of images for training image recognition models, which may prevent overfitting the network. Other work [14] also reported using self-collected data from the authors’ laboratory for demonstration.
It is very often necessary to obtain a region-of-interest (ROI) from an image for proper recognition. Hence, different image segmentation techniques have been implemented with varying degrees of success. These techniques include manual cropping with a combined matched filter and a local binary fitting model to locate tiny boundaries (small veins) in images [15]. The image centroid technique is also used for the segmentation of DHVs [16]. The major drawbacks of these manual segmentation techniques are the loss of significant information, they are time and labor-consuming, and there is high variability in the produced results because the process is based on judgments made using subjective intuition.
Meanwhile, the automatic cropping technique is highly effective and time-saving in extracting DHV patterns. For instance, the determination of coordinates method has been adopted to achieve the ROI of an image [17]. A morphological operation (top-hat transformation) is another useful technique that adjusts the intensity values to increase the visibility of inconsistent image background pixels [18]. A hybrid technique combining the grayscale morphology method and local thresholding technique has been used for the similar task [19]. It was emphasized that image enhancement methods are necessary to improve the contrast of an image from its background [20]. Histogram equalization (HE) is the most widely used traditional enhancing method to improve the intensity of an image globally rather than in the area of interest [21]. Among the variations in HE, contrast-limited adaptive histogram equalization (CLAHE) has been found to be an effective method to enhance the targeted area of DHV images [16,17,22].
In addition to the machine learning (ML) techniques mentioned above, other related studies have adopted strategies, such as artificial neural networks [22] and the Mahalanobis distance method [23]. Other research [24] has used convolutional neural network (CNN)-based model for segmentation. Unlike conventional ML methods, which can be time-consuming for manually determining the features for DHV recognition [16], CNN is an increasingly popular tool for decision-making. A CNN model was first introduced by LeCun et al. [25] to make recognition training simple and time-efficient (in the automatic extraction of useful information). Many pre-trained CNN models are available for image processing applications, such as AlexNet, VGGNet, GoogLeNet, DenseNet, ResNet, and SqueezeNet. While most of these models are used for classification, some CNN models have been adopted for image segmentation problems. Nonetheless, traditional ML techniques have advantages and perform better than CNNs [24], especially when texture features are the primary information sources for decision-making. The classification accuracy of CNN models depends upon tuned hyperparameters and the nature of the dataset. Previous studies [2,11–13,26] used CNN techniques to recognize the pattern of DHV. On that note, a study [11] recommended using AlexNet, VGG16, and VGG19 due to their high training accuracy (i.e., 99%), but efforts had yet to be made to test the trained model against unseen data. Even though another study [13] included the testing of the AlexNet model trained with augmented (randomly rotated) images, entire-hand images without an ROI extraction were used as input. Thus, instead of vein patterns, the model may have been trained to recognize the hand contour or image shape. Those prior studies have also not considered the false acceptance rate (FAR) or the false rejection rate (FRR) in their evaluations. A robust and secure biometric system has both low FAR and FRR [27]. In this study, we introduced a hybrid system combining HE, thresholding, and morphological techniques for enhanced, effective, and time-saving segmentation of DHV regions as compared to the manual approach. This study compared the performance of AlexNet transfer learning using the manual and hybrid automatically segmented data due to its time-efficiency. We analyzed the performance of the model trained with the enlarged dataset and compared it with previous research.
II. Methods
This section describes the dataset and methods used in this study. All the simulations were carried out using MATLAB R2020b.
1. Dorsal Hand Vein Dataset
The dorsal hand vein images used in this study are from the Bosphorus database (www.bosphorus.ee.boun.edu.tr). This is an open-access resource with a collection of 1,575 images from different experimental conditions. In our investigation, a total of 1,500 dorsal hand images from 100 subjects were selected from the original 1,575 images to balance the data size for each class. The considered images included 1,200 left-hand images of the recruited subjects acquired under different activities, namely normal (or at rest), after carrying a 3-kg bag for a minute, after squeezing (closing and opening) an elastic ball for a minute, and after placing a piece of ice on the back of the hand. The remaining 300 images were of their right hand in at-rest condition.
2. Manual Segmentation
In the first experiment, the cropping process was performed manually. The main areas of interest were the center regions of the dorsal side of the hand. The identified regions were outlined and segmented from the original images one at a time by using the imcrop function available in MATLAB, as shown in Figure 1. By doing this, the background and fingers were removed from the original image, leaving the region containing the hand veins. The selection was intuitive, and the process produced different image sizes. These images were resized to a dimension of 227 × 227 × 3 to match the input size of AlexNet prior to training.
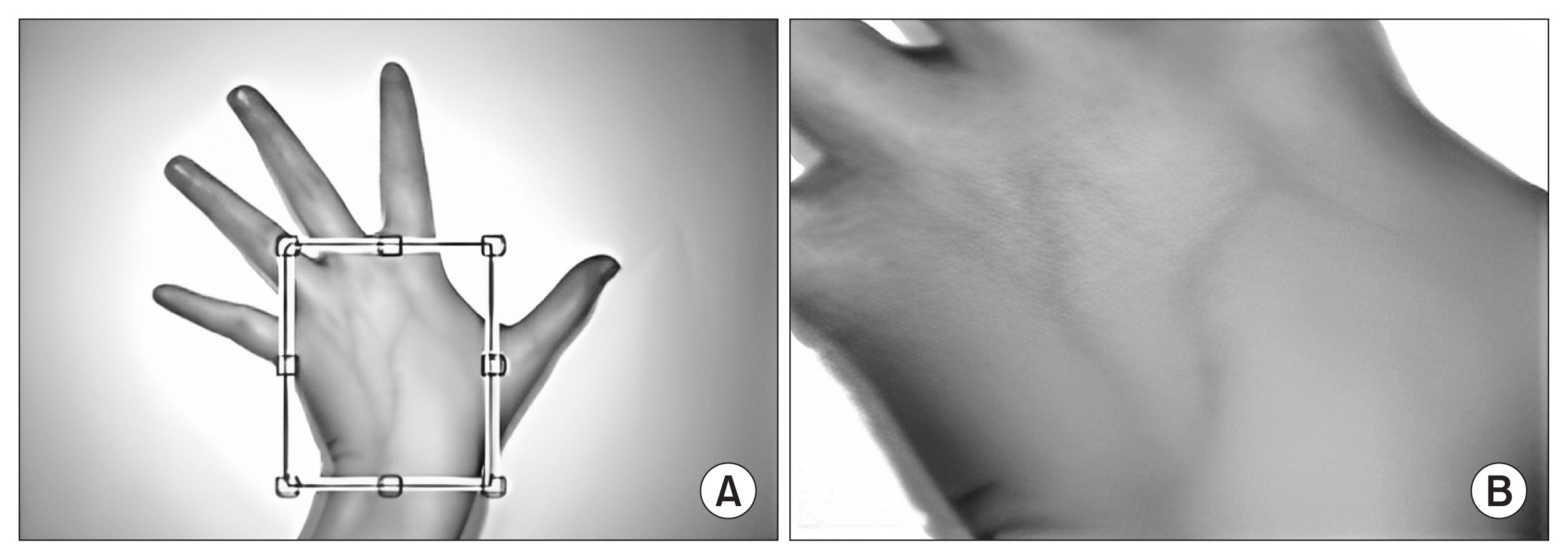
Manual cropping process: (A) defined boundary box of an image and (B) segmented output.
3. Hybrid Automatic Segmentation
The second experiment involved ML techniques to extract the ROI of DHVs. Since most ML techniques work in the grayscale color space, the first step was to convert the color image to gray using the rgb2gray function, as shown in Figure 2. The edges of the hand images were then enhanced with the CLAHE method. Next, all images were changed into binary versions by invoking the imbinarize function prior to performing morphological operations. In our study, morphological structuring elements (disks) with radii of 5, 10, 15, and 20 were applied to binary images to define the mask for the regions of interest. The morphological bottom-hat technique was also applied to the mask to filter the ROI of DHVs (vein portion) for this same purpose. This was followed by color inversion of the image using the imcomplement function and the pixel-difference method to locate the vein regions. The generated mask was overlaid on the original image to remove the fingers. The resulting image was thresholded by setting pixels with a value greater than 0.7 as NaN (i.e., an invalid number). This value is arbitrarily chosen for better smoothing quality. A mask frame was then introduced on the left and right sides of the original images to block the edges with lower pixel values (due to shadowing), which may have similar intensity as the vein’s region. The processed image was again converted to binary before applying the mask to remove the remaining background. CLAHE was then applied to further enhance the appearance of the vein region. In the final step, a thresholding operation was applied to the enhanced image to obtain a clearer visualization of the image, as shown in Figure 2. Finally, the produced images were resized to 227 × 227 × 3 before further processing. Since this method is mainly based on hybrid histogram analysis and morphological operations, hereafter, we refer to this approach as the HHM method.
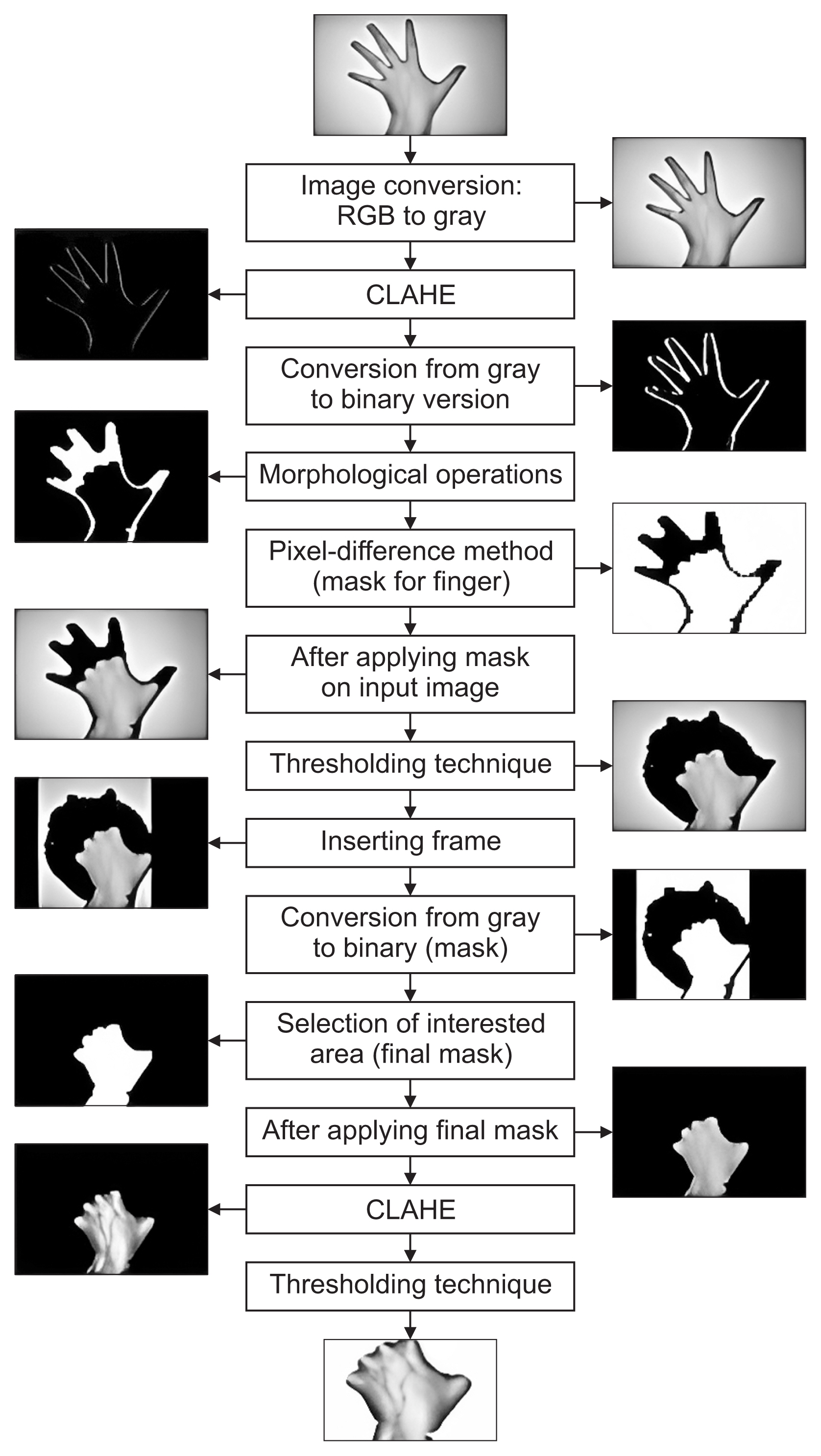
Flowchart of hybrid automatic segmentation (i.e., the HHM method). CLAHE: contrast-limited adaptive histogram equalization, HHM: hybrid automatic segmentation method.
4. Data Augmentation
After segmentation, the training dataset was augmented and split into training, validation, and testing sets at an 8:1:1 ratio, and their distribution is shown in Table 1. We used a constant random seed number of 10 in the dataset division process to ensure consistency in our comparisons. The training dataset was enlarged through augmentation using randomAffine2d and flip functions to improve the model performance. This process was done by random rotation of the images in two different angle intervals, (−30°, 30°) and (−50°, 50°), and random horizontal flipping, as shown in Figure 3.
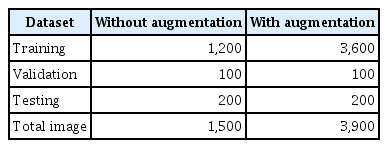
Distribution of images for training, validation, and testing of the model

Example of data augmentation operations on a segmented image.
5. Transfer-Learning AlexNet
Despite the lightweight and simple features of AlexNet, it produced comparable classification accuracy to its deeper counterparts, such as VGG16, ResNet-50, and SqueezeNet [26], suggesting its efficiency in extracting important information. Thus, AlexNet was used for our experiments. This model was trained with the manually and automatically segmented dataset shown in Figure 4. In these experiments, we froze the entire network backbone, except the last three layers—that is, the fully connected layer was replaced with 100 nodes corresponding to 100 users, softmax, and output. Stochastic gradient descent with momentum (SGDM) was employed as the solver due to its shorter computational time and high accuracy. The model trained with the manually segmented dataset was used as the gold standard for identifying the optimal training hyperparameters using the grid search approach. For this purpose, 50 trials were attempted. We adjusted the epoch, initial learning rate, and mini-batch size while keeping the rest of the parameters fixed. The epoch number was varied from 10 to 90 at a step of 10; the batch-size number was adjusted from 21 to 211, and the learning rates ranged from 0.00009 to 0.1 at a resolution of 0.00001. Our results showed that an epoch number of 50, an initial learning rate of 0.0008, and a mini-batch size of 128 were the best hyperparameters that yielded the best training and validation accuracies. This combination was chosen for the remaining experiments using other strategies, as shown in Table 2. Since it was our intention to demonstrate the efficiency of the proposed HHM method, the best model trained with the HHM was chosen based on the highest test accuracy. The quality of this biometric verification system was then evaluated in terms of the FAR and FRR. We considered threshold values of 0.3 and 0.5 following a previous recommendation [28]. A decision threshold of 0.5 has been deemed the most optimal in many studies in the field.
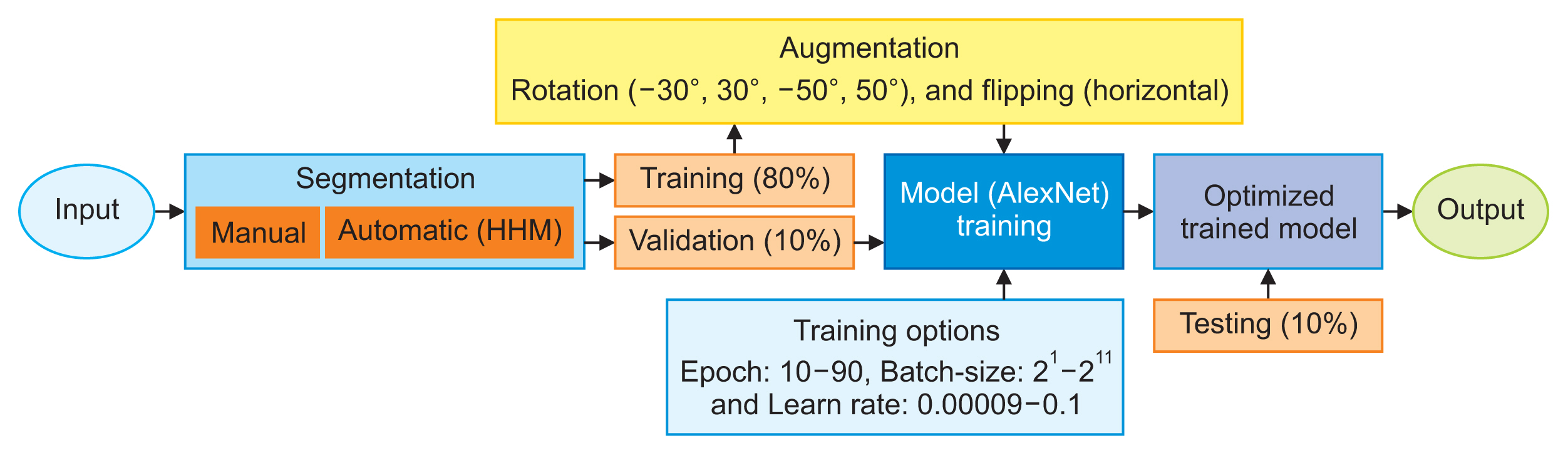
Schematic diagram of the dorsal hand vein processing and training workflow. HHM: hybrid automatic segmentation method.
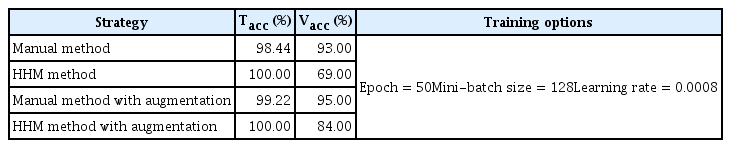
Training (Tacc) and validation accuracy (Vacc) of the model trained using the data processing strategies and training parameters adopted in this study
III. Results
This section presents the results obtained from training AlexNet, as well as a comparison of our results with the state-of-the-art.
1. Model Training
The training accuracy (Tacc) and validation accuracy (Vacc) of the model trained following the implementation of different strategies in Table 2 were obtained using the best combination of hyperparameters identified using the manual segmentation approach on original-size data. The improvement in the classification results with the inclusion of augmentation data is consistent with the observations in many previous studies [7,13]. The proposed HHM technique produced 100% Tacc compared to the manual method using both the original and augmented datasets. The computing time of the model trained with the inclusion of augmented data was approximately three times longer than the model trained with the original data.
2. System Performance and Comparison with Existing Methods
The test accuracy of the AlexNet model trained using the datasets segmented via the different strategies in Table 2 is shown in Figure 5. The models trained with the augmented dataset produced higher accuracy than those without augmentation. The manually segmented dataset achieved higher test accuracy than automatic segmentation. This difference was comparatively small with the augmented dataset. To further our research, we compared our results with the findings of published papers using AlexNet for the same problem [11,13,26]. Some of those studies used a different dataset and employed different strategies than ours in improving the test accuracy. Since the best model trained with the HHM method was the model that included augmentation, as shown in Figure 5, this model was used to test the efficiency of the biometric system. Our results showed mean FAR and FRR values of 0.00065% and 0.07% at a score threshold of 0.3, and 0.00035% and 0.095% with a 0.5 threshold.

Test accuracy of the model trained with datasets segmented using the manual and HHM methods, and with and without an augmentation strategy. HHM: hybrid automatic segmentation method.
IV. Discussion
In this study, we demonstrated the performance of AlexNet models trained using manually and automatically segmented datasets. We tested our models with an independent (unseen) dataset, and we did not consider a cross-validation (CV) scheme in the performance validation of the model because concerns have been raised about the grossly over-optimistic results from the CV method due to its lack of independent and external validation [29]. The manual method took nearly 20 working days using our CPU (Intel Core M-5Y71 with a 1.40 GHz processor and 8 GB of RAM) in segmenting the 1,500 images. This was three times longer than the time required for the HHM model. Based on the pre-experiment results, we found that tuning the training hyperparameters—namely, the mini-batch size, learning rate, and epoch number—was sufficient to enhance classification accuracy. We identified an epoch number of 50 as optimal for the employed model to learn important features using the segmented image dataset and minimize underfitting. Similarly, the mini-batch size value was tuned to 128. A large mini-batch size resulted in the training taking longer to reach convergence, while setting the value too low led to unstable learning problems that affected the overall classification performance. The best initial learning rate of 0.0008 was identified after running the network multiple times with different values. A small value caused the training procedure to take a long time, while a large value caused an unstable training process. During these tuning processes, we noticed significant changes in the training and validation accuracies, ranging between 80% and 98.44% and between 38% and 93%, respectively, using the manually segmented dataset as the benchmark set. This combination was found to work acceptably well for other strategies. Even though the test accuracy from the HHM method (non-augmented case) shown in Table 2 was lower than that achieved with the manual method, the performance of the model improved considerably to 84% with the inclusion of augmented data. Interestingly, in the manual method, it was found that the existing datasets may be sufficient for the network to learn all the important features. Hence, the inclusion of augmentation did not significantly improve the classification performance.
It must be mentioned here that there was evidence of model overfitting (Tacc = 100%) in the HHM method, which we attribute to the improper segmentation of certain images. The main cause of this was the highly consistent pixel values between the vein regions and undesired regions (i.e., background and fingers), resulting in either over-segmented or under-segmented results in certain images. The automatically and manually segmented datasets combined with the augmentation method produced generally better test accuracy values of 88% and 91.5%, respectively, as compared to those without augmentation (76.5% and 87.5%, respectively), shown in Figure 5. This suggests the possibility of improved model learning of deeper representations with greater variation in the training data. We do not rule out the possibility that the results would improve with a deeper and wider network for the extraction of more complex and richer features. The test accuracy in Figure 5 is consistent with the validation accuracies observed in Table 2, wherein the inference accuracy showed a notable improvement of more than 10% using the model trained with HHM-segmented data combined with an augmentation strategy.
A comparison with earlier works [13,26], as presented in Table 3, showed consistency with our results regarding the efficacy of augmentation. One study [11] used the original (hand) images without segmentation; thus, the model may have been trained to recognize the hand shape, instead of the vein pattern, which may be inappropriate for authentication tasks.
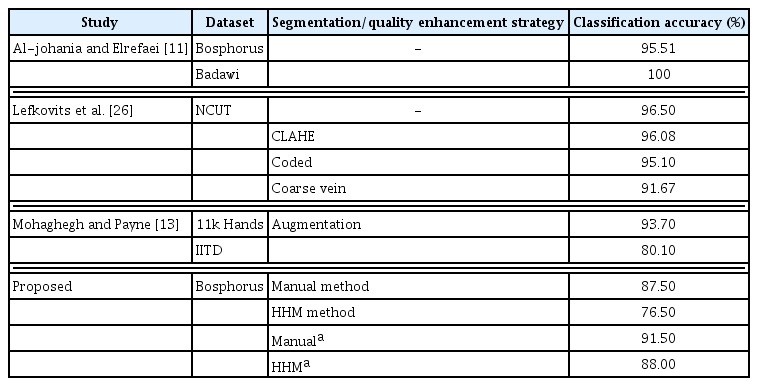
Comparison of classification accuracy between our method and the state-of-the-art
It is found that a manually segmented dataset produced a generally higher classification accuracy at the price of a more laborious and time-consuming procedure. There was also substantial inconsistency in the judgment process. In contrast, our automatic strategy is time-saving, requires less effort during segmentation, and produces repeatable results. This method can be suitably used for practical purposes due to its relatively low FAR and FRR, which were 0.00035% and 0.095% at a cutoff threshold of 0.5. These values were close to those obtained using a commercial biometric system [30], with a reported FAR and FRR of 0.0001% and 0.01%.
Nonetheless, there is still a need for a robust segmentation method to overcome the over-segmentation or under-segmentation problems that occur in 20% of images. This may be achieved with the use of hybrid ML and CNN, which may be explored in the future.
Notes
Conflict of Interest
No potential conflict of interest relevant to this article was reported.
Acknowledgment
Communication of this research is made possible through monetary assistance by Universiti Tun Hussein Onn Malaysia (UTHM) Publisher’s Office via Publication Fund E15216.